









Development Status of AI Chips at Home and Abroad
2021-06-13
If we say that the man-machine war between AlphaGo and Li Shishi in March 2016 only had a big impact in the tech community and the chess industry, then in May 2017, it would compete with Ke Jie, the world’s number one chess champion, to artificial intelligence. Technology has been pushed into public view. AlphaGo is the first artificial intelligence program to beat the human professional Go players and the first to defeat the world champion of Go. It was developed by a team led by Google’s DeepMind company, Dames Hasabis. The principle is "deep learning."

In fact, as early as 2012, deep learning technology has caused extensive discussion in the academic community. In this year's ImageNet Large-scale Visual Identity Challenge ILSVRC, AlexNet, a neural network architecture with 5 convolutional layers and 3 fully connected layers, achieved the best historical error rate of top-5 (15.3%). The second place scored only 26.2%. Since then, there have emerged more neural network structures with more layers and more complex structures, such as ResNet, GoogleNet, VGGNet, and MaskRCNN, as well as the generative countermeasure network GAN that was developed last year.
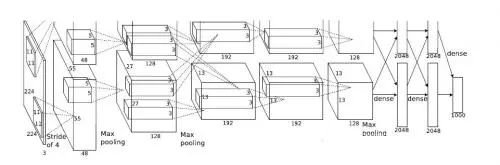
Whether it is winning AlexNet for the visual recognition challenge, or defeating Keqi’s AlphaGo, their realization cannot be separated from the core of modern information technology—processors, whether they are traditional CPUs or GPUs, or emerging. The dedicated acceleration component NNPU (NNPU is short for Neural Network Processing Unit).
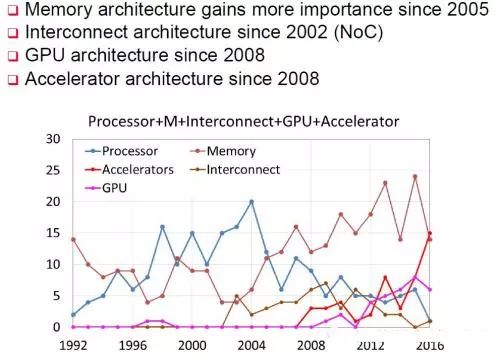
At the International Top Conference on Computer Architecture ISCA 2016 there was a small seminar on Architecture 2030. Prof. Xie Yuan from UCSB, a Hall of Fame member, summarized the papers that were included in ISCA since 1991, and the relevant accelerometer related articles were included. It began in 2008 and peaked in 2016, exceeding the three traditional areas of processors, memory, and interconnect architecture. In this year, the "Neural Network Instruction Set" paper submitted by the research group of Chen Yunyi and Chen Tianshi from the Institute of Computing Technology, Chinese Academy of Sciences, was the highest scored paper for ISCA 2016.
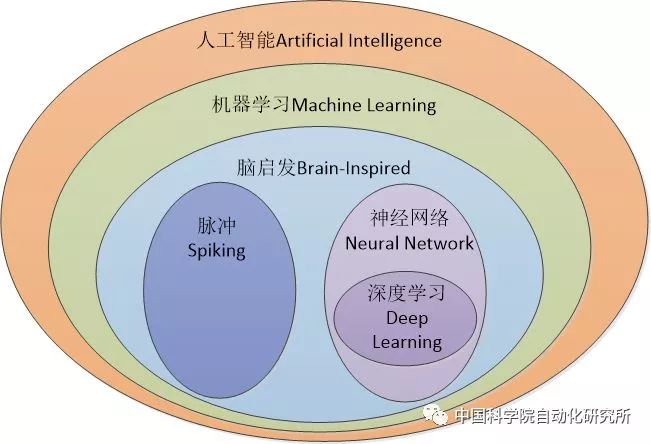
Before specifically introducing the AI chip at home and abroad, it appears that some readers may have such doubts: Isn't it all about neural networks and deep learning? So I think it is necessary to elaborate on the concepts of artificial intelligence and neural networks, especially in the “Three-year Action Plan for Promoting New Generation of Artificial Intelligence Industry Development (2018-2020)” issued by the Ministry of Industry and Information Technology in 2017. The description of development goals is very It is easy to make people think that artificial intelligence is a neural network, and AI chips are neural network chips.
The overall core basic capabilities of artificial intelligence have been significantly enhanced, smart sensor technology products have achieved breakthroughs, and design, foundry, and packaging and testing technologies have reached international standards. The neural network chip has been mass-produced and has achieved large-scale application in key areas. The open source development platform has initially supported the industry. Rapidly developing capabilities.
In fact, it is not. Artificial intelligence is a very old and old concept, and neural networks are only a subset of the artificial intelligence category. As early as 1956, John McCarthy, the Turing Award winner known as the "Father of Artificial Intelligence," defined artificial intelligence in this way: Creating the science and engineering of intelligent machines. In 1959, Arthur Samuel gave a definition of machine learning in a subfield of artificial intelligence, that is, "computers have the ability to learn, rather than through pre-accurately implemented code," which is now recognized as the earliest and most accurate machine learning. Definition. The neural networks and deep learning that we all know daily belong to the category of machine learning and are all inspired by the brain mechanism. Another important area of research is the pulsed neural network. Domestically represented units and enterprises are the Brain Computing Research Center of Tsinghua University and Shanghai Xijing Technology.
Well, now we can finally introduce the development status of AI chips at home and abroad. Of course, these are my personal observations and my humble views.
Foreign technology oligarchs have obvious advantages
Thanks to its unique technology and application advantages, Nvidia and Google account for almost 80% of the market for artificial intelligence processing, and after Google announced its Cloud TPU open service and Nvidia launched the Xavier, it’s a share. In 2018, it is expected to further expand. Other vendors, such as Intel, Tesla, ARM, IBM and Cadence, also have a place in the field of artificial intelligence processors.
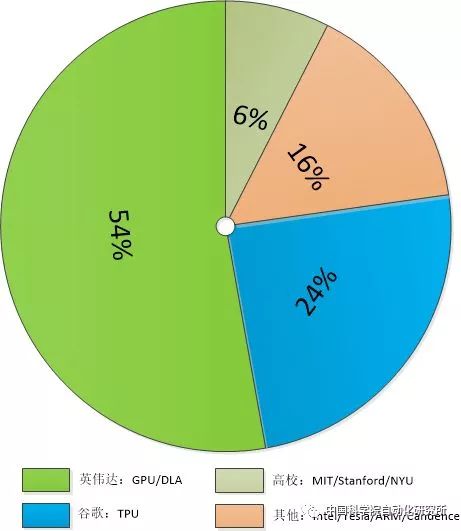
Of course, the focus areas of these companies are not the same. For example, Nvidia mainly focuses on GPUs and unmanned areas, while Google focuses on the cloud market, Intel focuses on computer vision, and Cadence provides acceleration-related neural network computing-related IP. If the aforementioned companies are mainly biased toward hardware areas such as processor design, then ARM is mainly software oriented and is dedicated to providing efficient algorithms for machine learning and artificial intelligence.
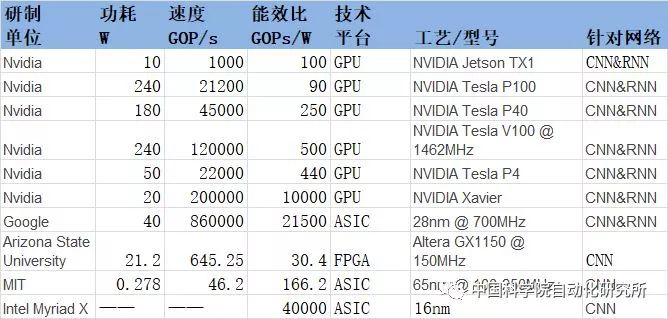
Note: The above table gives the most up-to-date data available to all development units by 2017.
1. Take the lead in the game - Nvidia
In the area of artificial intelligence, Nvidia can be said to be the company with the most extensive coverage and largest market share. Its product lines are found in many areas such as self-driving cars, high-performance computing, robotics, healthcare, cloud computing, and game videos. Its Xavier, a new artificial intelligence supercomputer for the field of self-driving cars, in the words of NVIDIA CEO Jen-Hsun Huang: "This is an amazing attempt in the area of SoC that I know. We have long been committed to developing chips."

Xavier is a complete system-on-chip (SoC) that integrates a new GPU architecture called Volta, a custom 8-core CPU architecture, and a new computer vision accelerator. The processor provides high performance of 20 TOPS (trillion operations per second) while consuming only 20 watts. A single Xavier AI processor with 7 billion transistors, manufactured using cutting-edge 16nm FinFET processing technology, can replace the DRIVE PX 2 currently equipped with two mobile SoCs and two independent GPUs while power consumption is just one Small part.
At CES Las Vegas in 2018, NVIDIA introduced three Xavier-based artificial intelligence processors, including a product that focuses on the application of augmented reality (AR) technology to automobiles, and a further simplified vehicle. DRIVE IX, built and deployed by the artificial intelligence assistants, and a modification of its own proprietary taxi brain, Pegasus, further expand its advantages.
2、Integration of production, education and research - Google
If you just know Google's AlphaGo, driverless and TPU, and other artificial intelligence related products, then you should also know the technology behind these products: Google legend chip engineer Jeff Dean, Google cloud computing team chief scientist, Stanford University of AI laboratory director Li Feifei, Alphabet chairman John Hennessy and Google outstanding engineer David Patterson.
Today, Moore's Law has met with both technical and economic bottlenecks, and processor performance has been growing at a slower pace. However, the demand for computing power has not slowed down in society, even in mobile applications, big data, and labor. With the rise of new applications such as intelligence, new requirements have been put forward for computational power, computational power consumption, and computational cost. Unlike traditional software programming models that rely entirely on general-purpose CPUs and their programming models, the overall system of heterogeneous computing includes a variety of domain-specific architecture (DSA)-designed processing units, each with a DSA processing unit. Responsible for the unique field and optimization for this area, when the computer system encounters the relevant calculations by the corresponding DSA processor to be responsible. Google is the practitioner of heterogeneous computing. TPU is a good example of heterogeneous computing in artificial intelligence applications.

The second-generation TPU chip released in 2017 not only deepened the ability of artificial intelligence in learning and reasoning, but also Google seriously to market it. According to Google's internal tests, the second-generation chips can save half the training time for machine learning than the GPU on the market. The second-generation TPU includes four chips and can handle 180 trillion times per second. Point operations; if you combine 64 TPUs together and upgrade to so-called TPU Pods, you can provide about 11,500 trillion floating-point operations.
3, computer vision field disruptors - Intel
Intel, as the world's largest computer chip maker, has been seeking a market other than computers in recent years, and the battle for artificial intelligence chips has become one of Intel’s core strategies. In order to strengthen its strength in the field of artificial intelligence chips, not only the acquisition of Altera, an FPGA manufacturer, for 16.7 billion US dollars, but also the acquisition of Mobileye, an autopilot technology company, as well as machine vision company Movidius and a company that provides security tools for self-driving car chips for US$15.3 billion. Yogitech highlights the positive transformation of the giant, who is at the core of the PC era, towards the future.

Myriad X is the visual processing unit (VPU) vision component (VPU) introduced by Movidius, an Intel subsidiary, in 2017. It is a low-power system-on-chip (SoC) for accelerating deep learning and manual operations on vision-based devices. Smart - such as drones, smart cameras and VR / AR helmets. Myriad X is the world's first system-on-a-chip (SoC) equipped with a dedicated neural network computing engine to accelerate deep learning inference calculations on the device side. The neural network computing engine is an on-chip integrated hardware module designed for high-speed, low-power and deep-learning-based neural networks without sacrificing accuracy, allowing devices to see, understand, and respond to the surrounding environment in real time. With the introduction of this neural computing engine, the Myriad X architecture provides 1TOPS computational performance for deep learning based neural network inference.
4, the implementation of "energy efficiency ratio" of the ears - academia
In addition to the continuous introduction of new products by the industrial community and manufacturers in the field of artificial intelligence, the academic community is continuing to promote the development of new technologies for artificial intelligence chips.
Bert Moons of the University of Leuven in Belgium presented the ENVEN chip for accelerating convolutional neural networks with an energy efficiency ratio of up to 10.0 TOPs/W using the 28nm FD-SOI technology. The chip includes a 16-bit RISC processor core, 1D-SIMD processing unit for ReLU and Pooling operations, 2D-SIMD MAC array processing for convolutional and fully-connected layer operations, and 128 KB of on-chip memory.
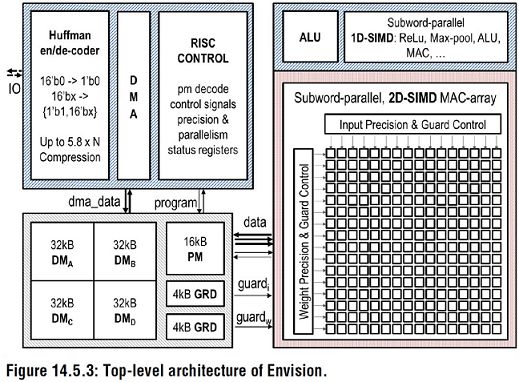
Dongjoo Shin et al. of KAIST, Korea Academy of Science and Technology, presented a configurable accelerator unit DNPU for CNN and RNN structures at ISSCC 2017. In addition to a RISC core, it also includes a computational array CP for convolutional layer operations. A computational array FRP for fully-connected-layer RNN-LSTM operation compared to Envision at the University of Leuven, DNPU supports CNN and RNN structures, and the energy efficiency ratio is as high as 8.1 TOPS/W. The chip uses a 65nm CMOS process.
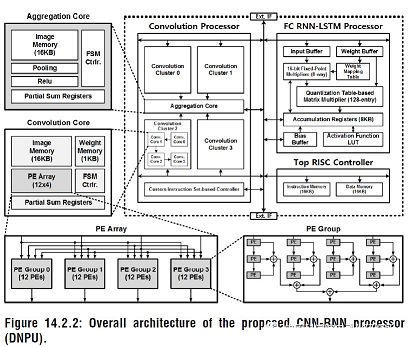
Comparing with the computing operations of the Leuven University and the Korea Science and Technology Institute for the neural network inference part, Venkataramani S et al. of Purdue University proposed an artificial intelligence for large-scale neural network training at ISCA2017, the top conference for computer architecture. Processor SCALLDEEP.
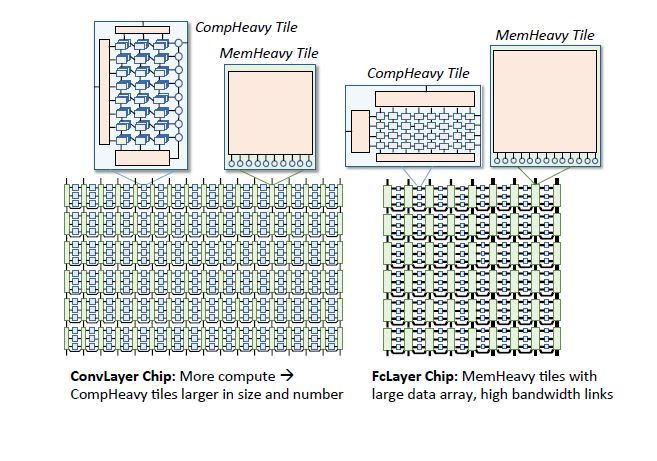
This paper aims at the optimization of the training part of the deep neural network, proposes an extensible server architecture, and deeply analyzes the computational intensity and the density of visits in the deep neural network such as the convolution layer, the sampling layer, and the fully connected layer. Different aspects, the design of the two processor core architecture, the computationally intensive tasks in the comHeavy core, contains a large number of 2D multipliers and accumulator components, and for access-intensive tasks are placed in the memHeavy core , contains a large number of SPM memory and tracker synchronization unit, both for use as a storage unit, but also for calculations, including ReLU, tanh and so on. A SCALEDEEP Chip can be composed of two types of processor cores in different configurations and then compose a cluster.
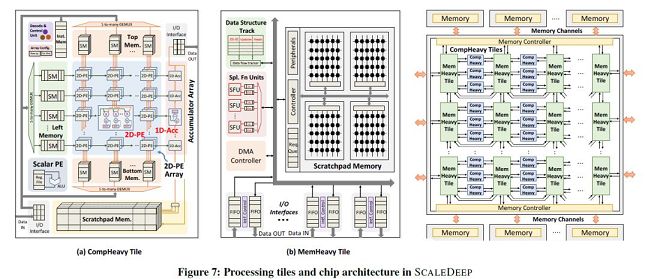
The processing platform used in the paper includes 7032 processor tiles. The author of this paper designed a compiler for deep neural networks to complete network mapping and code generation. At the same time, a simulator for designing space exploration was designed to evaluate performance and power consumption, and the performance benefited from a clock-accurate simulator. The power consumption evaluation extracts the net-list parameter model of the module from the DC. The chip only uses the Intel 14nm process for synthesis and performance evaluation, peak energy efficiency as high as 485.7GOPS/W.
Controversy among the domestic ones, their own governance
It can be said that there is still a big gap between the development and application of various units in the field of artificial intelligence processors compared with foreign countries. Due to China's special environment and market, the development of domestic artificial intelligence processors presents a trend of flourishing and contending, and the applications of these units are spread across many fields such as stock trading, finance, commodity recommendation, security, early education robots, and driverlessness. A large number of artificial intelligence chip startup companies, such as Horizon, Shenzhen Institute of Technology, Chinese Cambrian, etc. In spite of this, the Cambrian period in China, which started earlier in China, has not formed the same market scale as the foreign giants. Like other manufacturers, there is a fragmented development in their own right.
In addition to emerging start-up companies, domestic research institutions such as Peking University, Tsinghua University, and Chinese Academy of Sciences have conducted in-depth research in the field of artificial intelligence processors; other companies such as Baidu and Bitland have also released some results in 2017.
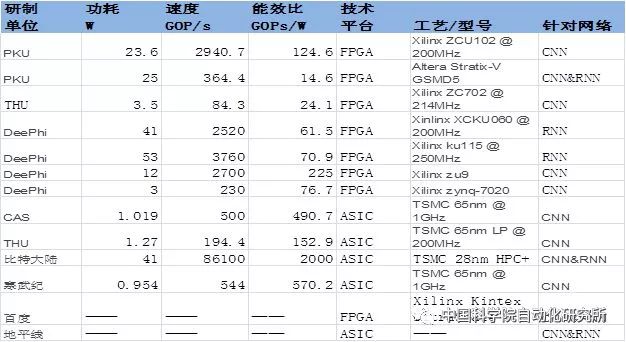
Note: The above table gives the most up-to-date data available to all development units by 2017.
1, the world's first AI chip community unicorn - Cambrian
In August 2017, the domestic AI chip startup company Cambrian announced that it had completed a round of 100 million U.S. dollars of round A financing. Strategic investors can be said to be lineups of luxury. Companies such as Alibaba, Lenovo, and HKUST Telecom are involved in investment. The company has also become the world’s first unicorn in the AI chip industry and has received extensive attention from domestic and foreign markets.
Cambrian Technology is mainly responsible for the R&D and production of AI chips. The company's main product is the Cambrian-1A processor (Cambricon-1A) released in 2016. It is a deep-learning neural network dedicated processor for smart phones. Various types of terminal equipment such as drones, security monitoring, wearable devices, and smart driving, etc., are superior to conventional processors in the performance and power ratio of running mainstream intelligent algorithms. At present, various models such as 1A and 1H have been developed. At the same time, the Cambrian also introduced Cambricon NeuWare, a Cambrian artificial intelligence software platform for developers, which includes three parts: development, debugging, and tuning.
2, a model of collaborative development of hardware and software - Shen Jian Technology
Shen Song, co-founder of Shen Jian Technology, has repeatedly mentioned the importance of hardware and software co-design for artificial intelligence processors on various occasions, and its best in the FPGA field conference FPGA2017 best paper ESE hardware architecture is the best proof. This work focuses on the scene of speech recognition using LSTM. Combining Deep Compression, special compilers, and an ESE-dedicated processor architecture, it can achieve 3 times higher performance than Pascal Titan X GPUs on midrange FPGAs. And reduce power consumption by 3.5 times.
In October 2017, Shenzhen Shenjian Technology Co., Ltd. launched six AI products: Face Detection and Identification Module, Face Analysis Solution, Video Structured Solution, ARISTOTLE Architecture Platform, Deep Learning SDK DNNDK, and Binocular View. Deep Vision Suite. In terms of artificial intelligence chips, the latest chip plan was announced. The “Tingtao” and “View of the Sea” chips independently developed by Shenzhen Shenjian Technology will be available in the third quarter of 2018. The chip adopts TSMC's 28nm process technology. Dodd architecture, peak performance 3.7 TOPS/W.
3, the standard Google TPU - Bit Continental count abundance
The Bitcoin, a bitcoin unicorn, entered the field of artificial intelligence in 2015. Its tensor processor Sophon BM1680 for AI applications released in 2017 is another specialized version of the world after Google TPU. The ASIC for accelerated tensor calculation is suitable for training and reasoning of CNN / RNN / DNN.

The BM1680 single-chip can provide 2TFlops single-precision acceleration computing capability. The chip is composed of 64 NPUs. The specially designed NPU scheduling engine (SPU) can provide powerful data throughput capabilities and input data to the Neuron Processor Cores. The BM1680 uses an improved systolic array structure. In 2018, Bitcontin will release the second generation BF1682 AI chip, which will greatly increase the computing power.
4. A hundred schools of thought - Baidu, Horizon and others
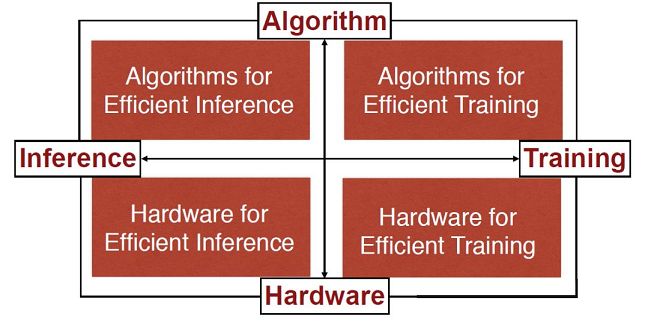
At the HotChips conference in 2017, Baidu released XPU, a 256-core, FPGA-based cloud acceleration chip for Baidu's artificial intelligence, data analysis, cloud computing, and driverless business. At the meeting, Baiyang researcher Ouyang Jian stated that Baidu's designed chip architecture highlights diversity, focusing on computationally intensive, rule-based tasks while ensuring maximum efficiency, performance, and flexibility.
Ouyang Jian said: "FPGA is efficient, can focus on specific computing tasks, but the lack of programmability. Traditional CPU is good at general-purpose computing tasks, especially rule-based computing tasks, but also very flexible. GPU aimed at parallel computing, so there are With very strong performance, XPU is concerned with computationally intensive, rule-based, diverse computing tasks, hoping to increase efficiency and performance, and bring about CPU-like flexibility.
In 2018 Baidu disclosed more relevant information about XPU.
At the end of December 2017, the artificial intelligence startup Horizon released China’s first global leading embedded artificial intelligence chip – the Journey 1.0 processor for smart driving and the Sunrise 1.0 processor for smart cameras. There are three intelligent application solutions for smart driving, smart city and smart business. "Rising Sun 1.0" and "Journey 1.0" are artificial intelligence chips developed entirely by Horizon and have world-leading performance.
In order to solve the problem in the application scenario, Horizon has made a strong coupling between the algorithm and the chip, used algorithms to define the chip, improved the efficiency of the chip, and ensured its low power consumption and low cost in the case of high performance. There are no public data for specific chip parameters.

In addition to Baidu and Horizon, domestic research institutions such as the Chinese Academy of Sciences, Peking University, and Tsinghua University also have published results related to artificial intelligence processors.
The Peking University Joint Venture Technology Co., Ltd. proposed a fast FPGA-based Winograd algorithm that can significantly reduce the complexity of the algorithm and improve CNN performance on the FPGA. The experiments in this paper use the best currently available CNN architectures (such as AlexNet and VGG16) to achieve optimal performance and energy consumption under FPGA acceleration. On the Xilinx ZCU102 platform, the average convolution layer processing speed was 1006.4 GOP/s, the overall AlexNet processing speed was 854.6 GOP/s, the convolution layer average processing speed was 3044.7 GOP/s, and the overall VGG16 processing speed was 2940.7 GOP/s.
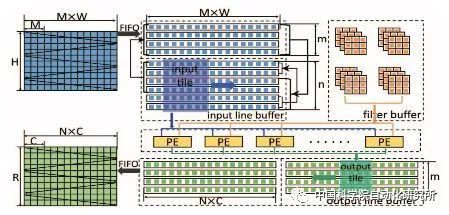
The State Key Laboratory of Computer Architecture of the Chinese Academy of Sciences proposed a data flow-based neural network processor architecture at the top conference HPCA2017 to adapt to parallel computations such as feature maps, neurons, and synapses in order to achieve this goal. The team redesigned a single processing unit PE so that the operands can be acquired directly from the on-chip memory via a horizontal or vertical bus, whereas non-legacy PEs can only be acquired by neighboring units from top to bottom or from left to right. The chip uses a TMSC 65nm process with a peak performance of 490.7 GOPs/W.

At the 2017 VLSI International Symposium, Wei Shaojun, Department of Microelectronic and Nanoelectronics of Tsinghua University, Thinker, a neuro-computing chip based on reconfigurable multimodality, was proposed. Thinker chip is based on the long-term reconfigurable computing chip technology accumulated by the team. It adopts reconfigurable architecture and circuit technology, breaks through the bottleneck of neural network computing and memory access, and realizes energy-efficient multi-modal mixed-neural network computing. The Thinker chip has the outstanding advantage of high energy efficiency, and its energy efficiency is improved by three orders of magnitude compared to the GPU currently widely used in deep learning. The Thinker chip supports circuit-level programming and reconstruction. It is a universal neural network computing platform that can be widely used in robotics, drones, smart cars, smart homes, security monitoring and consumer electronics. The chip uses a TSMC 65nm process with on-chip memory of 348KB and a peak performance of 5.09TOPS/W.

5. New Architecture New Technologies - Memristors
In 2017, Qian He and Wu Huaqiang of Tsinghua University’s Institute of Microelectronics published online research entitled “Face Classification using Electronic Synapses” in Nature Communications. The scale of the integration of oxide memristors has been increased by an order of magnitude, and brain-like calculations based on 1024 oxide memristor arrays have been achieved for the first time. This achievement achieves the integration of storage and calculation on the most basic single memristor, adopting a completely different system than the traditional “von Neumann architecture”, which can reduce the power consumption of the chip to less than one thousandth of the original. Memristors are considered to be the most potential electronic synapse devices. By applying a voltage across the device, it is possible to flexibly change the state of its resistance to achieve synaptic plasticity. In addition, memristors have the advantages of small size, low power consumption, and large-scale integration. Therefore, the brain-like computing hardware system based on memristor has the advantages of low power consumption and high speed, and has become a hot spot in international research.

In terms of neuromorphic processors, the most famous is IBM's TrueNorth chip, which was introduced in 2014. The chip includes 4096 cores and 5.4 million transistors, consumes 70mW, simulates one million neurons and 256 million synapses. . In 2017, Intel also launched Loihi, a self-learning chip that can simulate brain work. Loihi consists of 128 computational cores. Each core integrates 1024 artificial neurons and the entire chip has more than 130,000 neurons. With 130 million synaptic connections, compared to more than 80 billion neurons in the human brain, the scale of Loihi's operation is only a little more complicated than that of a shrimp brain. Intel believes that the chip is suitable for autonomous driving of drones and automobiles, traffic lights with adaptive traffic conditions, and the use of cameras to find missing people and other tasks.

In the field of neuromorphic chip research, Shi Luping, a brain-like computational research center at Tsinghua University, launched the first brain-like chip, the “Sky Motion Core”, in 2015. The world’s first artificial neural network (ANNs) ) and Spiking Neural Networks (SNNs) for heterogeneous integration, taking into account both mature technology and widely used deep learning models and computational neuroscience models with great future potential, such as image processing, speech recognition, and target Tracking and other application development. In the brain-like “self-propelled” car demonstration platform, 32 Tianji No. 1 chips were integrated, and cross-modal brain-based information processing experiments targeting visual target detection, perception, target tracking, and adaptive attitude control were implemented. It is reported that the second-generation chip based on TSMC's 28nm process is also coming soon, and the performance will be greatly improved.

Looking at the development trend of artificial intelligence chips from ISSCC2018
At the just-concluded top conference of computer architecture ISSCC2018, Byeong-Gyu Nam, chairman of the "Digital Systems: Digital Architectures and Systems" sub-forum, summarized the development trend of artificial intelligence chips, especially deep learning chips. Deep learning is still the hottest topic this year. Compared to last year's most papers discussing the realization of convolutional neural networks, this year is more concerned about two issues: First, if more effective implementation of convolutional neural networks, especially for handheld terminals and other equipment; Second, It is about full-connected non-convolutional neural networks, such as RNN and LSTM.
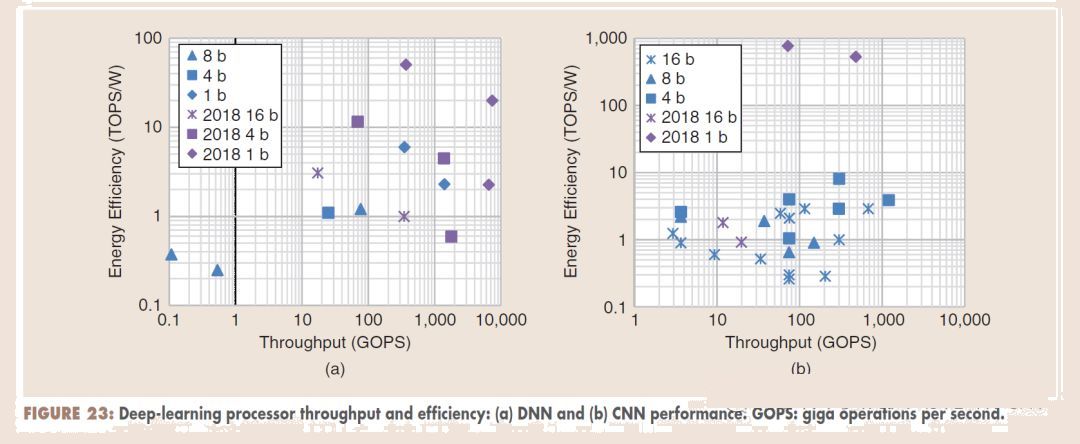
At the same time, in order to obtain a higher energy efficiency ratio, more and more researchers are focusing on the design and implementation of low-precision neural networks, such as 1bit neural networks. These new technologies have enabled the energy efficiency ratio of deep learning accelerators to increase from a few dozen tones last year to a hundred toes this year. Some researchers also studied digital + analog mixed-signal processing implementations. For full-connected networks that require high data access, some researchers rely on 3-D packaging technology for better performance.
As mentioned above, in the field of artificial intelligence chips, foreign chip giants occupy most of the market share, and they have absolute leading edge in terms of talent accumulation and company merger. The domestic artificial intelligence start-up companies also presented a turmoil of contending and self-government. In particular, each start-up company’s artificial intelligence chips have their own unique architecture and software development kits, which cannot integrate into the ecosystems established by Nvidia and Google. Do not have the strength to compete with it.
The development of domestically produced artificial intelligence chips, like the development of domestically produced general-purpose processors and operating systems in the early years, has been excessively pursuing a completely independent, autonomous and controllable cycle, and is bound to gradually withdraw from the stage of history as many domestic chips. Thanks to the complete ecosystem of X86, in just one year, SMIC's domestically-manufacturable x86 processor and Lenovo's domestic computer and server designed and manufactured based on SMIC CPU have been highly recognized by party and government officials throughout the country. , And has been applied in batches in the national key systems and projects such as the party, government and military office and informatization.
Of course, the X86 ecosystem has nothing to do with generic desktop processors and high-end server chips. After all, creating an ecological chain like Wintel is no easy task, and we cannot meet the second Jobs and Apple. In the field of new artificial intelligence chips, there is still much room for development for many domestic chip manufacturers. The most important point for the neural network accelerator is to find an application field with broad prospects, such as Huawei's Hessian Kirin processor. In the Cambrian NPU of the Department of Medicine; otherwise it is necessary to integrate into a suitable ecosystem. In addition, most domestic artificial intelligence processors are currently accelerating for neural network calculations, and few can provide single-chip solutions; in the field of microcontrollers, ARM's Cortex-A series and Cortex-M series occupy the leading role. However, the emerging open-source instruction set architecture RISC-V can not be underestimated. It is totally worth the attention of many domestic chip manufacturers.
Embark on a vibrant aquatic adventure with our inflatable ride-on-a playful and eye-catching addition to your poolside escapades. This buoyant and colorful ride on pool floats is designed for those who seek excitement and joy in every splash.
Crafted with quality materials, our inflatable ride-on ensures a sturdy and comfortable experience as you explore the pool. The vibrant design adds a pop of color to the water, creating an inviting and lively atmosphere for all ages. The ride-on's construction strikes the perfect balance between softness and durability, ensuring hours of fun without compromising on resilience.
Let your imagination run wild as you navigate the pool on our vibrant ride-on. The thoughtful design includes sturdy handles for a secure grip, allowing riders of all ages to confidently steer through the water. Whether you're hosting a pool party or enjoying a solo dip, this inflatable ride-on is your ticket to endless aquatic excitement.
Easy to inflate and deflate, our inflatable ride on toy is a convenient companion for impromptu pool adventures. The lightweight and portable nature of the inflatable make it ideal for beach trips, pool parties, or simply lounging under the sun. Unleash the vibrant spirit of summer with this engaging and playful ride-on, ensuring that every pool session becomes a thrilling exploration.
Transform your pool into a lively playground with our vibrant ride on float. Dive into the refreshing waters, create lasting memories, and let the colors of fun and excitement infuse your aquatic experiences. Elevate your poolside adventures with this cheerful and buoyant ride-on, inviting everyone to explore the pool in style.
Float Rider, Inflatable Rider, Pool Float Unicorn, Inflatable Flamingo
Mengzan Hometex Co., Ltd. http://www.jminflatablepool.com